In our earlier post you have learned about the HANA concept (in-memory ram, multi core processor, columnar storage, data compression, massive parallel processing).
If you have not visited our earlier post, please go through once from the below link.
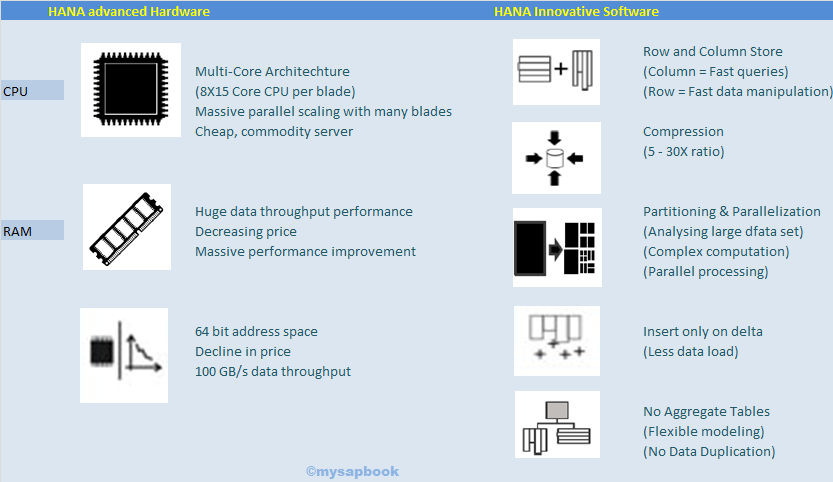
Now it's clear that HANA is not only database, it's a platform, combination of advanced hardware and innovative software.
So, as an ABAPer is there anything new?
Yes.
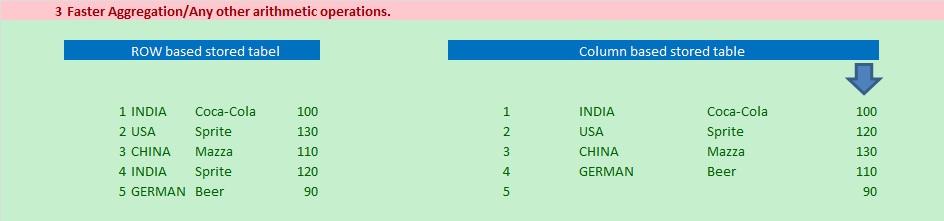
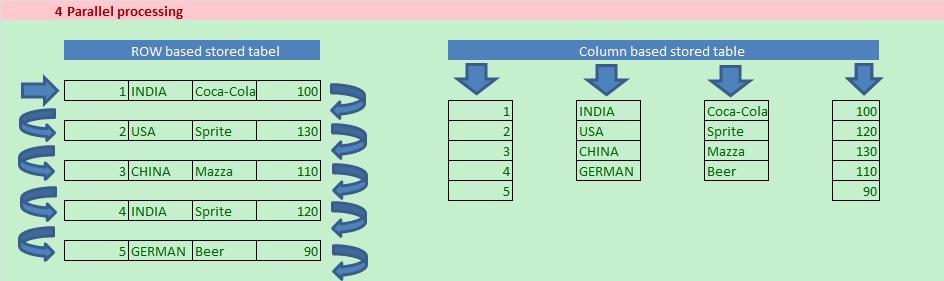
If we can take any of our developed programs, we can see there are database table select to fetch data based on our requirements and then we do loop, all the required calculations, filtering of data based on conditions, populating final internal tables etc.
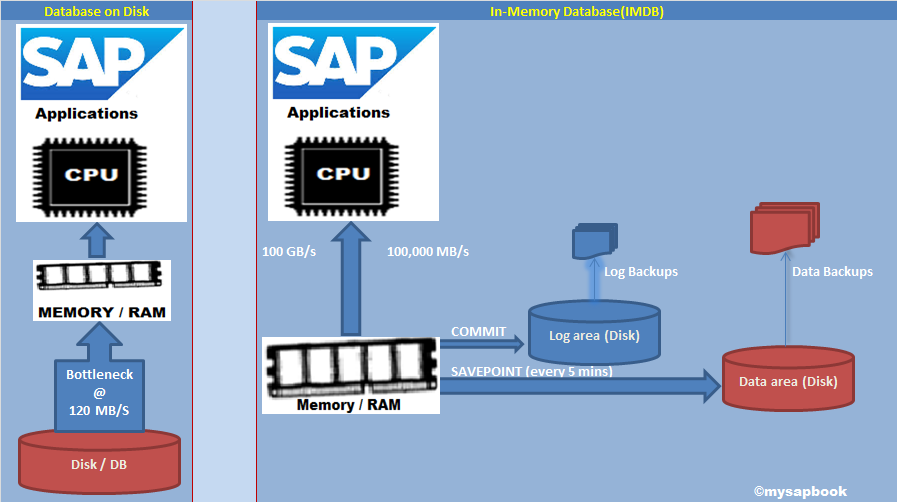
That means after simple database tables hits from database server we are pulling data into application server to process and get our required output/results.
In this way we may pulling, keeping, processing with unwanted data which may overload the database hit, extra pulling cost from database to application server and overburden the application server with unnecessary data processing.
Now, as the HANA brings total database in in-memory (very near to application server or we can say inside the application server), so now why we will hit database tables as we did earlier only to fetch data and do all the complex processing in application server, rather we can do all the data processing/calculation/populations while doing the database query/operations.
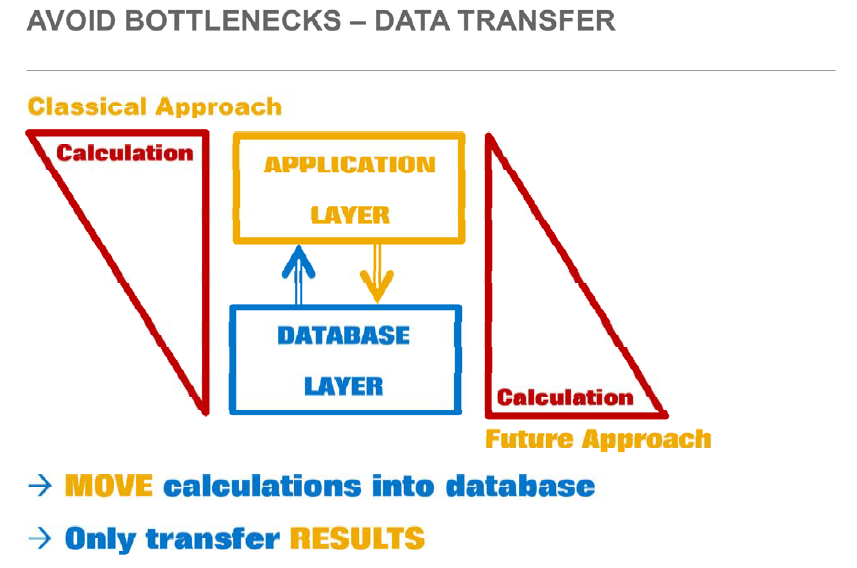
Image Source: SAP HANA – HA100
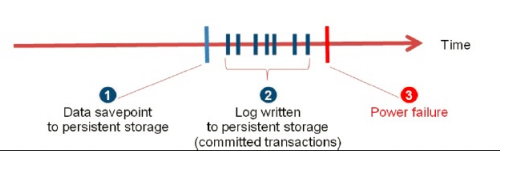
If we want to follow in the above concept then I'm sure you will be agree with me that our database query should be robust enough to avoid the application server logics overhead.
If your answer is yes then only I will go ahead :)
I'm sure you understood it properly and your answer is YES.
So what is the big deal now for an ABAPer.
ABAPer need to more concentrate on the database query rather than the application server custom logics.
As of now we are writing database query in open SQL.
After HANA came into picture we have started writing native SQL.
Now one of my friends raises his hand and asked hey Partha, what is this native/open SQL?
I know you don't require this kind of education now but still I'll explain for my friends who are unaware of this like my previous friend.
Open SQL:
SAP is supporting this open SQL to make query to any kind of database (oracle, DB2) that means it is independent of database provider and open to all.
Basically SAP has its own dictionary objects that are also independent of any kind of database and Open SQL works on that dictionary objects. After that the query goes to the specific database through the database interface that SAP have in the format of Native SQL.
You can also easily identify the Native SQL if you try to see any database query/Open SQL in SQL trace from ST05.
Native SQL:
As the name itself says that the query language is native to specific database. So when we will be using HANA as a primary database then we need to write our database query in Native SQL, the same way the SAP database interfaces is converting our open SQL into native SQL while going from dictionary query to database specific query.
HANA Evaluation:
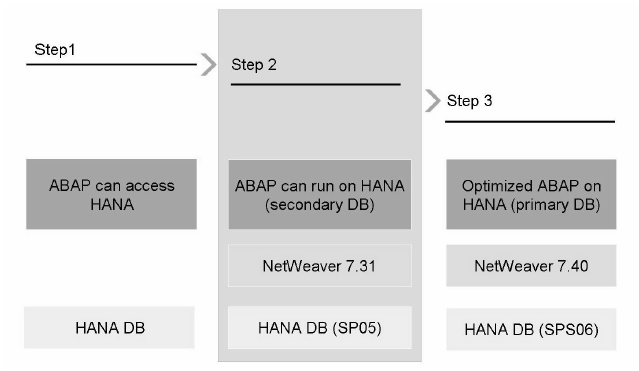
Image source: SAP HANA – HA400
Obviously your company, who are already running their business in SAP, will not go and migrate to HANA overnight. As they already having their existing database to do business and after knowing the HANA's robust features, they are trying to replace their existing database systems by bringing HANA as secondary database and looking for permanent replaced the information near future.
So now your company have HANA as secondary database.
Transaction DBACOCKPIT:
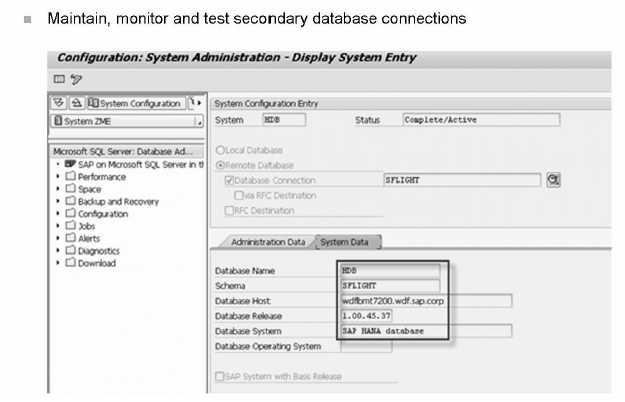
Image source: SAP HANA – HA400
Now as an ABAPer one question would definitely come in our mind.
We have already written tones of code, so will all our code be replaced now if we want to use HANA as secondary database?
Definitely not!
Still we can keep our old code, written in open SQL query with little modifications like below.
Here SAP has come up with one new keyword 'CONNECTION', which will basically bypass our database query from traditional database to HANA database.
Open SQL using secondary database connection:
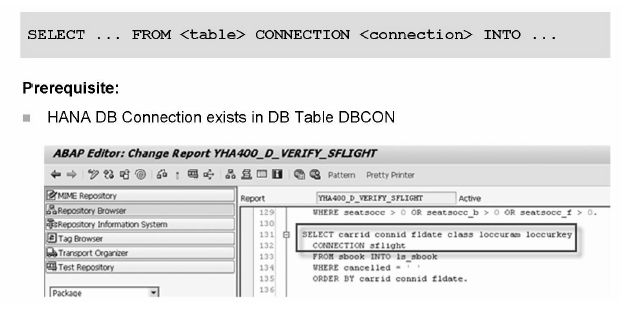
Image source: SAP HANA – HA400
Sometimes we are using HANA as secondary database with 'CONNECTION' when we need secondary index in our traditional database tables and to avoid the additional overhead of secondary indexes we are approaching to HANA database which doesn't bother about indexes as it is column storage and all the fields behaves as primary key.
But we have some restrictions as well if we only using HANA as secondary database. Which are as below.
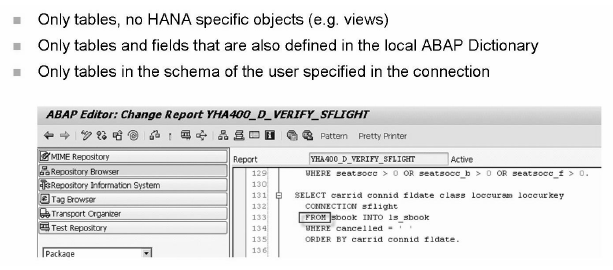
Image source: SAP HANA – HA400
So we need to gradually move towards the HANA as primary database.
Primary database means, as I have already discussed as an ABAPer we need to move into Native SQL.

Image source: SAP HANA – HA400

Open SQL Syntax and Native SQL Syntax:
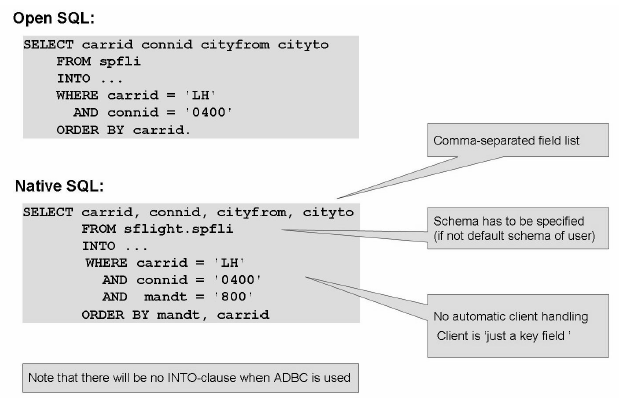
Image source: SAP HANA – HA400
Join in OPEN and Native SQL:

Image source: SAP HANA – HA400
How we can connect to HANA when we are using as primary database?
The answer is ADBC.
So let's have some idea about ADBC as well in this platform.
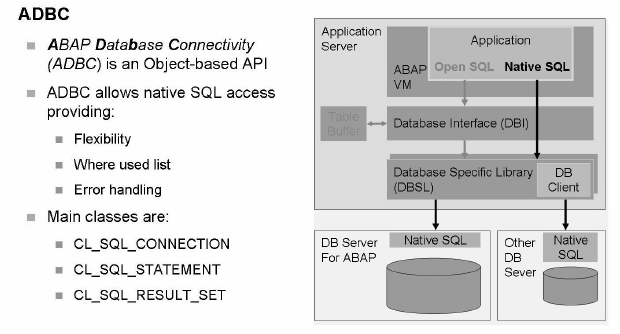
Image source: SAP HANA – HA400
Sequence for Reading Data with ADBC:
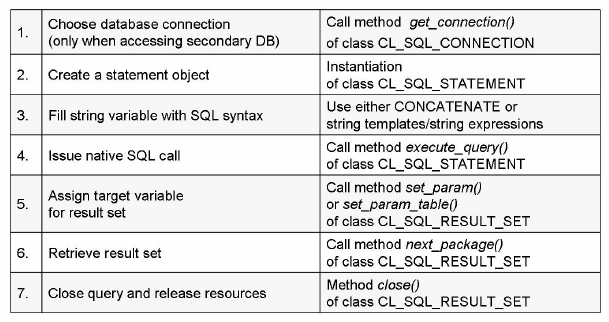
Image source: SAP HANA – HA400
Coding Example: ABAP Database Connectivity (ADBC):

Image source: SAP HANA – HA400
ADBC: Important things to keep in mind:

Gradually we will learn about Schema, SQL Script, Procedures
Different views - attribute view, analytical view, calculation view and lot...
After reading the post you would definitely gain some interest to begin with HANA code.
But you have not HANA server to play around!! ☹
Don’t worry buddy! ☺
You can access HANA cloud platform for free. My dear friend Raju explained it in absolutely easy way.
Please go through the below link and grab it.
Stay tuned and be with us!